
Il progetto SpikingBrain nasce in Cina con un obiettivo ambizioso: costruire modelli linguistici che non solo parlino come un essere umano, ma che si avvicinino al modo in cui il cervello elabora le informazioni. I ricercatori hanno introdotto un’architettura che integra neuroni spiking e meccanismi di attenzione ibrida, cercando di superare la rigidità delle reti tradizionali. Il risultato è un modello che promette di gestire testi di lunghezza estrema con una rapidità e un’efficienza mai viste prima.
La promessa di efficienza con contesti infiniti
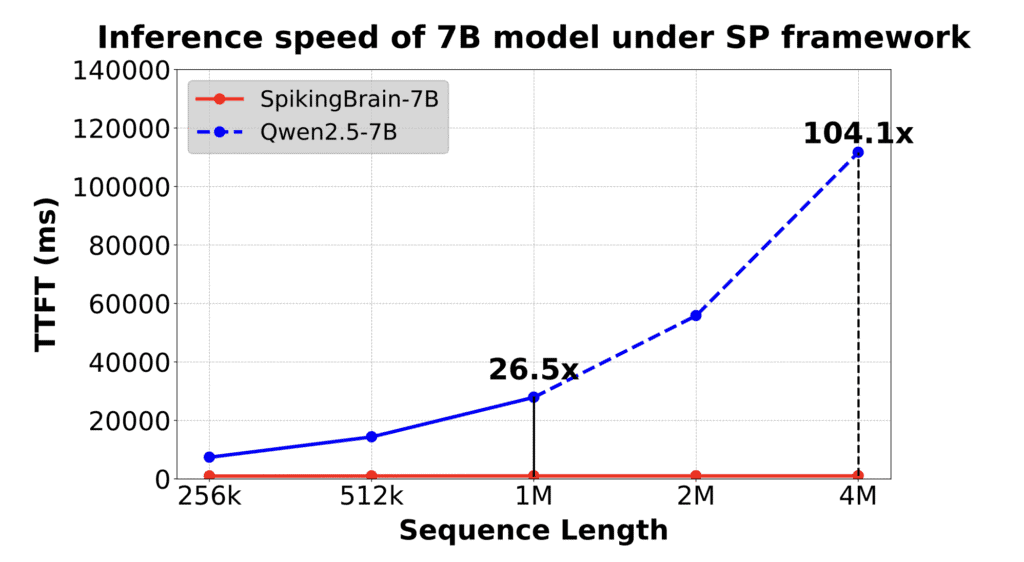
Uno dei grandi ostacoli dei Large Language Models è la gestione di sequenze molto lunghe. Con il classico approccio, il costo computazionale cresce in modo quadratico: ogni token deve confrontarsi con tutti gli altri. SpikingBrain rovescia la logica introducendo un sistema di attenzione ibrida lineare, che consente di elaborare contesti di milioni di token riducendo drasticamente tempi e consumi. Nei test dichiarati, il modello SpikingBrain-7B ha raggiunto una velocità di generazione fino a 100 volte superiore nel “time to first token” rispetto ai modelli convenzionali.
Hardware alternativo e indipendenza strategica
Un aspetto che rende SpikingBrain ancora più interessante è il suo addestramento. Non si è fatto affidamento sulle tradizionali GPU NVIDIA, ma su cluster MetaX, una piattaforma hardware alternativa sviluppata in Cina. Questa scelta non è solo tecnica ma geopolitica: significa ridurre la dipendenza da fornitori occidentali, aprendo scenari di indipendenza tecnologica e di accesso più flessibile a risorse di calcolo massicce. In un contesto globale in cui il controllo delle GPU è diventato un nodo cruciale, SpikingBrain rappresenta una dichiarazione di autonomia.
Dati ridotti, impatto aumentato
Il team sottolinea anche un altro dato sorprendente: per addestrare SpikingBrain non è stato necessario ricorrere alle stesse montagne di token usate dai giganti occidentali. Attraverso pipeline di conversione e “continual pre-training”, i ricercatori sono riusciti a ottimizzare la qualità senza disperdere risorse. Questo approccio permette di ridurre i costi energetici e accelerare i cicli di sviluppo, aprendo la porta a un’IA che non dipende solo dalla quantità di dati ma dalla loro organizzazione.
Luci e ombre di un modello sperimentale
Nonostante l’entusiasmo, gli analisti mettono in guardia: la definizione di “spiking” è più vicina a una simulazione che a un reale utilizzo di hardware neuromorfico. In altre parole, l’efficienza straordinaria è in parte il frutto di ottimizzazioni matematiche più che di un salto radicale verso il cervello artificiale. Inoltre, le prestazioni spettacolari potrebbero dipendere da condizioni di test molto specifiche. Resta comunque un passo importante, perché segnala la direzione che l’IA potrebbe prendere: meno consumo, più intelligenza ispirata alla biologia.
Leggi anche LLM e calcoli: perché l’intelligenza artificiale fallisce nei preventivi
Perché SpikingBrain conta
SpikingBrain non è solo un esercizio accademico. È il simbolo di un cambio di paradigma: i prossimi modelli non si limiteranno a diventare più grandi, ma proveranno a diventare più intelligenti e sostenibili. Se riuscirà a mantenere le promesse, potremmo essere di fronte a un nuovo standard per i modelli di linguaggio: cervello-inspired, efficienti, indipendenti. Un’innovazione che non riguarda soltanto la ricerca, ma anche le applicazioni pratiche: dalla gestione di enormi archivi legali, alla traduzione di testi infiniti, fino al training di sistemi per la sicurezza nazionale.