
Negli ultimi anni i modelli linguistici di grandi dimensioni – da GPT a Gemini – hanno mostrato capacità straordinarie di generare testi, risolvere problemi e comprendere contesti complessi. Tuttavia, dietro questa potenza si nasconde un limite strutturale: una volta addestrati, questi modelli restano statici. Non imparano realmente dall’esperienza, non aggiornano la propria conoscenza e non si evolvono in modo autonomo.
Il Massachusetts Institute of Technology (MIT) ha deciso di affrontare direttamente questa frontiera con una ricerca che potrebbe cambiare la traiettoria del settore: Self-Adapting Language Models (SEAL), un framework in grado di far sì che i modelli si aggiornino da soli, imparando in modo continuo e senza supervisione umana diretta.
Un nuovo paradigma di apprendimento
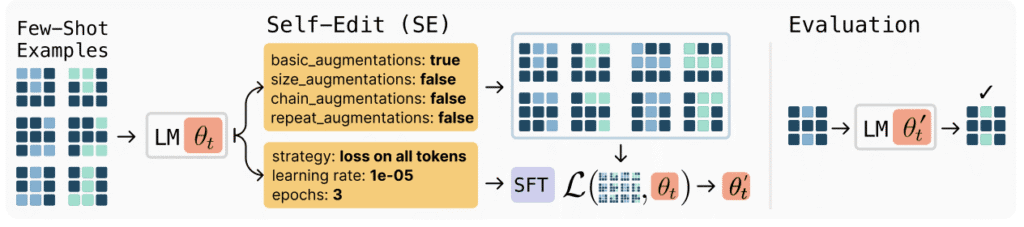
L’idea alla base di SEAL è tanto ambiziosa quanto elegante. Invece di affidarsi a nuovi dataset o a procedure di fine-tuning manuale, il modello stesso genera “self-edits”, ossia micro-lezioni su ciò che deve apprendere.
Quando entra in contatto con nuove informazioni – un testo, un evento, un fatto aggiornato – il sistema elabora come potrebbe integrare quella conoscenza, produce esempi sintetici, istruzioni e possibili domande e poi utilizza questo materiale per riaddestrarsi in modo mirato. In pratica, scrive i propri appunti di studio e li usa per migliorare.
La ricerca, pubblicata dal MIT CSAIL (Computer Science and Artificial Intelligence Laboratory), mostra che SEAL è capace di apprendere nuovi concetti e mantenerli nel tempo, con performance superiori ai modelli tradizionali su compiti di comprensione e integrazione della conoscenza.
Il ciclo interno dell’adattamento
Il processo si articola in due fasi principali. Nel cosiddetto inner loop, il modello genera e applica i propri “self-edits”, modificando in minima parte i pesi interni attraverso un fine-tuning mirato. Successivamente, nell’outer loop, valuta se queste modifiche hanno effettivamente migliorato la sua capacità di rispondere correttamente ai task di riferimento.
Questo doppio ciclo permette al sistema di sviluppare una forma primitiva ma concreta di metacognizione: non solo apprende, ma impara anche a capire come migliorare il proprio modo di apprendere. È un passo verso una forma di intelligenza che non si limita a usare informazioni ma che ragiona sul proprio processo di apprendimento.
I risultati e il codice open source
Nei test condotti su benchmark di conoscenza e ragionamento, SEAL ha mostrato un aumento medio di accuratezza fino al 47 % su compiti di incorporazione della conoscenza, rispetto al 32 % dei modelli statici. Nei test di few-shot learning, in cui il modello deve dedurre regole generali da pochissimi esempi, ha raggiunto oltre il 70 % di successo, superando nettamente le alternative.
Il progetto è open source e disponibile su GitHub all’interno dell’iniziativa Continual-Intelligence, segnale di una volontà di apertura e collaborazione da parte del MIT verso la comunità scientifica globale. L’obiettivo dichiarato è far progredire la ricerca verso sistemi capaci di aggiornarsi in autonomia, riducendo la dipendenza da dataset centralizzati e costosi processi di addestramento.
Limiti dell’apprendimento continuo
Ma la promessa dell’autoadattamento porta con sé questioni non banali. Una delle principali è il cosiddetto catastrophic forgetting: quando un modello impara qualcosa di nuovo, rischia di dimenticare ciò che già sapeva. Il bilanciamento tra adattabilità e stabilità diventa quindi cruciale.
Inoltre, ogni ciclo di auto-apprendimento richiede risorse computazionali significative – il modello deve generare nuovi dati, riaddestrarsi e verificare i risultati – rendendo complesso l’utilizzo in tempo reale o su larga scala. Per ora SEAL funziona su modelli di dimensioni moderate e in contesti sperimentali, ma i principi che introduce sono applicabili a sistemi molto più grandi.
Leggi anche SpikingBrain: il modello ispirato al cervello che sfida i limiti dell’IA
Perché SEAL è una svolta
Più che una semplice evoluzione tecnica, SEAL rappresenta un cambio di prospettiva. Finora, l’intelligenza artificiale ha funzionato come una grande enciclopedia probabilistica, capace di consultare ma non di scrivere nuovi capitoli. Con l’auto-adattamento, i modelli iniziano invece a produrre conoscenza, trasformandosi in entità dinamiche che possono evolversi nel tempo.
In un futuro prossimo, ciò potrebbe tradursi in assistenti digitali che aggiornano le proprie competenze in autonomia, agenti che apprendono dai dati aziendali in modo controllato o sistemi di ricerca che migliorano costantemente le proprie ipotesi.
Una linea di confine tra controllo e autonomia
La domanda che questa tecnologia pone non è solo tecnica ma filosofica: quanto spazio siamo disposti a concedere all’autonomia dell’IA?
Un modello che decide cosa apprendere e come farlo diventa anche responsabile delle proprie trasformazioni. Serviranno quindi meccanismi di tracciabilità, verifica e trasparenza per comprendere come e quando il sistema modifica sé stesso.
Il MIT ha aperto una porta verso un nuovo livello di intelligenza artificiale. Sta ora alla comunità scientifica – e presto anche alle imprese – capire come attraversarla senza perdere il controllo sul percorso.
In sintesi
Il MIT introduce SEAL, un modello linguistico capace di apprendere da sé. Genera micro-lezioni per aggiornare la propria conoscenza, superando i limiti dei modelli statici. È open source, promette IA più autonome e apre nuovi interrogativi su controllo e trasparenza.